
Overview
Web3 applications must communicate with blockchain data through common access interfaces like REST or RPC. KYVE’s Trustless API enables developers to connect their applications to historical blockchain data archived and validated by KYVE within seconds. Plus, with a Merkle Proof attached, clients can be 100% sure the retrieved data is valid.
The Trustless API serves validated data for free, thereby making it accessible to everyone. It provides the data via well-known endpoints and allows the seamless integration of KYVE trustless data. For example, efficiently serving Ethereum blobs without having to run an Ethereum archival node. In this case, KYVE provides a deployed endpoint, instructions on how to run your own Trustless API, and covers a variety of potential usages.
Read more about the Trustless API in the following sections:
FAQ
What is the usage limit/pricing?
KYVE’s Trustless API is already live and can be leveraged via this endpoint. The endpoint itself lists the integrations that are currently supported.
All data made trustless by KYVE is a public good, free for all to leverage. The Trustless API is also free for all to use without a query limit, providing a process that requires no data storage, no major data downloading, and no node running. Just connect and build!
What makes the API trustless?
Two important hashes are stored on the KYVE chain during the data validation process. Firstly, the hash of the entire data bundle is stored, which contains a certain amount of data items (e.g. block 1 to 100). In addition, the Merkle root of a Merkle tree is stored, which is constructed from these data items. This Merkle root enables the Trustless API, as the integrity of individual data items (e.g. block 40) can also be guaranteed in this way. To achieve this, the Trustless API extends the actual data item with a proof that contains all the hashes required to calculate the Merkle root. This allows the data item to be hashed first and the Merkle root to be calculated using the hashes obtained. If this matches the Merkle root that was stored on-chain, the client can be sure that the data item has been validated by KYVE.
What does the use look like?
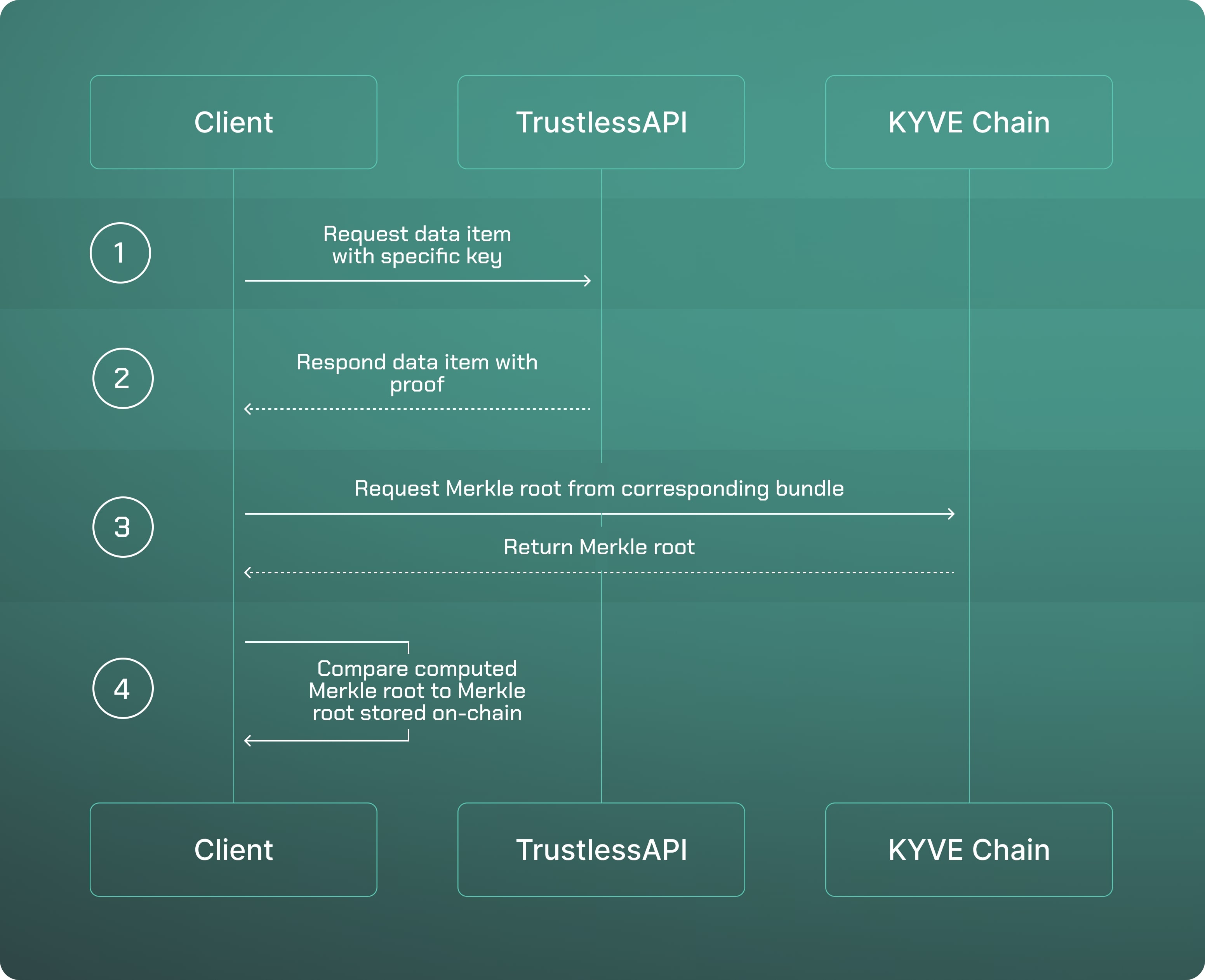
- The client requests a data item through a deployed Trustless API endpoint (e.g. https://data.services.kyve.network).
- The Trustless API responds with the data item, the created proof, and the metadata the client needs to get the correct Merkle root (
chain-id,pool-id,bundle-id). - The client requests the corresponding Merkle root from an independent KYVE node.
- After computing the Merkle root with the hash of the received data item and the received hashes in the proof by the Trustless API, the client compares it to the Merkle root stored on-chain. If it's the same, the data item has been validated by KYVE. If it differs, the data item hasn't been validated by KYVE.
What is the data item inclusion proof?
The data item inclusion proof allows one to check a data item’s validity without requiring one to download the whole bundle. Therefore, the bundle summary is extended with a Merkle root of a Merkle tree containing all data items.
When retrieving data, the Trustless API is responsible for serving data items and provides not only the requested item but also a proof that includes the leaves of the Merkle tree. This allows the client to hash the local data item and check if it's in the provided array. If found, the client can reconstruct the Merkle tree to verify the computed root against the one stored in the bundle summary on-chain.
This increases the efficiency of the inclusion proof significantly, because to ensure a data item's validity only the Merkle tree would need to be computed in order to perform a Merkle proof to check if the data item has been included in the bundle.
Why is it important to build with valid data?
Today, anyone can bring data on-chain and claim it’s true, creating a significant risk for those who might implement it into their project. On top of this, most blockchains leverage one or two archival nodes to keep track of their entire historical data, leading to centralization hazards such as single points of failure and data loss.
Historical data can also be stuck behind a paywall, restricting access and undermining transparency. The idea of a trustless environment emerged from the need to eliminate these risky sources, instead relying on network participants with distributed trust and incentivization to only bring forward valid data.
KYVE leverages this concept to streamline access to historical blockchain data in a trustless way, ensuring accuracy and reliability. This allows builders to avoid potential pitfalls and develop robust applications with confidence in their data's integrity.