Overview
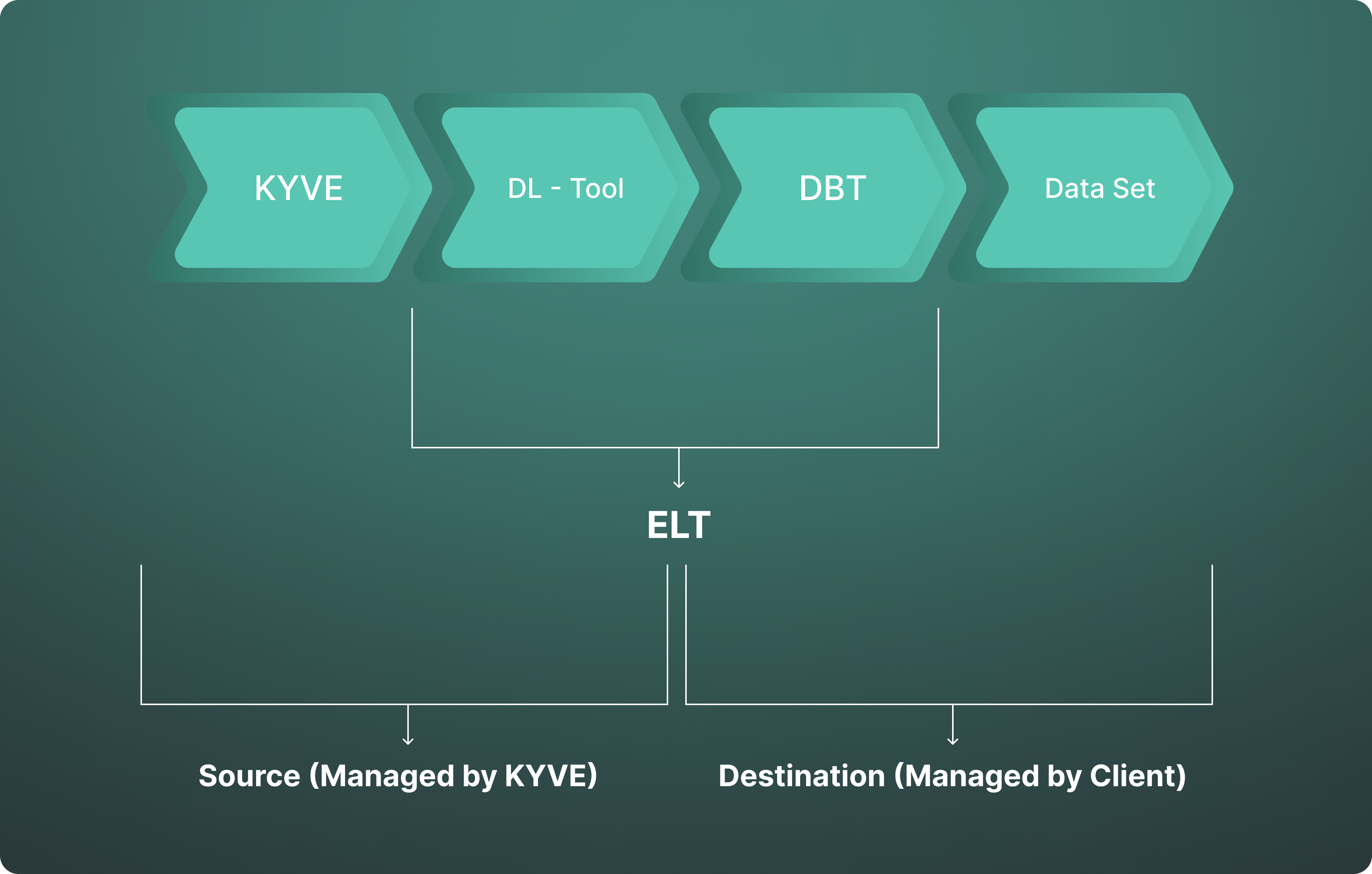
The KYVE Data Pipeline is a concept that outlines the flow of data coming from the KYVE Data Lake. Its goal is to establish an infrastructure that allows all KYVE data consumers to access and utilize data in an efficient and user-friendly manner, resulting in a comprehensive data set. The Data Pipeline is composed of four key components:
- KYVE Data Lake: The foundation where all validated data is stored and made available.
- Data Load Tool: A streamlined and efficient method for loading data from the KYVE Data Lake into the desired database.
- DBT: Data transformation using dbt to ensure it is readily accessible and usable in a Data Warehouse. (This pillar is currently under development and will be released soon.)
- Data Set: The ultimate goal of the Data Pipeline: a complete, up-to-date data set that meets all user requirements.