
Implementation
This section describes the implementation details of the Trustless API.
The Trustless API is divided into distinct components. First, the crawler retrieves bundles from KYVE, generates an data inclusion proof for each data item, creates indices, and stores them along with the data inclusion proofs.
Then, the server handles requests for data items by specific keys, retrieves the data item, and returns it with its data inclusion proof.
These components operate independently, so the crawler must be running to ensure the server can serve the crawled data items correctly.
Crawler
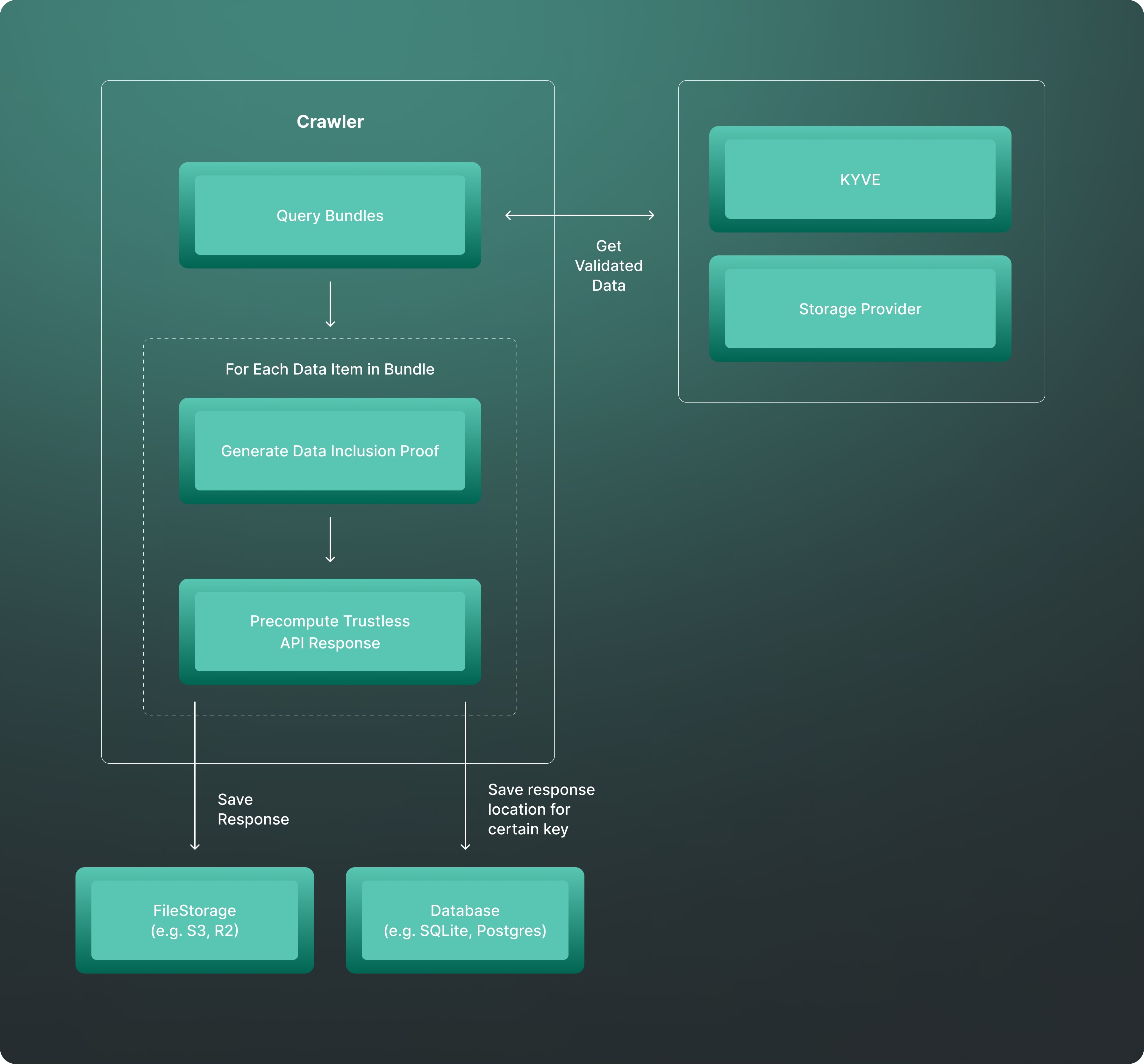
As previously mentioned, the crawler is responsible for retrieving all bundles from the KYVE chain and storing each data item. The crawler process knows which pools to query based on the config.yml file provided. You can find a template configuration under ./config/config.template.yml.
The config file contains all poolIds that should be crawled. The crawler itself functions like a master, starting one go-routine per poolId that is responsible for crawling that specific poolId.
Each go-routine (referred to as a ChildCrawler from here on) performs the following tasks:
- Query missing bundles
- For each data item in the bundle, the crawler
- generates a data inclusion proof for that specific data item,
- precomputes the Trustless API response,
- saves the precomputed response,
- and saves the response location for certain keys.
- Repeats that every n-seconds
Query Bundles
To insert a bundle, the following steps are required for the crawler:
- Query the specific bundle using the bundleId on the KYVE chain, where it is called finalizedBundle (the ChildCrawler will use the
chainrestdefined in the config as the node endpoint). - Retrieve the decompressed bundle data associated with the finalizedBundle from the storage provider (the ChildCrawler will use the
storagerestdefined in the config as the storage provider endpoint). - The decompressed bundle data is an array of data items. Compute the hash value of each data item to generate the data inclusion proof, enabling simple verification of whether a data item was included in a specific bundle.
Generate Data Inclusion Proof
With the bundle's data items and their corresponding hashes, the next step is generating trustless data items with their proofs of inclusion.
This involves iterating over each data item in the bundle and computing a compact Merkle tree for each one. The compact Merkle tree includes only the necessary hashes to construct the Merkle root, which matches the Merkle root stored on the KYVE chain.
Precompute Trustless API Response
Finally, the response is built, consisting of the actual data item and its corresponding inclusion proof. Additionally, relevant information such as the chainId, poolId, and bundleId is included for the user to verify the data item's Merkle root.
Save Response & Keys
As a final step, all responses are saved or uploaded to a file storage system, such as S3, and the location is stored in the database.
Indexer
Indices must be generated for each data item to enable quick retrieval of trustless data items based on specific keys. Each data item must have at least one index, but it can have multiple indices. The crawler generates indices according to the indexer defined in the config.yml.
The purpose of the indexer is to return the possible indices for a specific data item, which are then stored and later queried in the database.
Example: EthBlobs
The EthBlobsIndexer generates all necessary indices to query for blobs:
- block_height
- slot_number
This means, the EthBlobsIndexer will take a bundle, which is an array of data items, as an argument and return an array of trustless data items back. A trustless data item contains the actual data, the inclusion proof and all necessary information to verify that proof (like chainId and bundleId). Additionally it contains an array of indicies for that specific data item, these indicies will then be stored in the database to correctly retrieve the trustless data item later on.
func (e *EthBlobsIndexer) IndexBundle(bundle *types.Bundle) (*[]types.TrustlessDataItem, error) {
var trustlessItems []types.TrustlessDataItem
for index, dataitem := range bundle.DataItems {
// calculate inclusion proof
...
// calculate indicies
var indices []types.Index = []types.Index{
{Index: dataitem.Key, IndexId: IndexBlockHeight},
{Index: blobData.SlotNumber, IndexId: IndexSlotNumber},
}
trustlessDataItem := types.TrustlessDataItem{
Value: raw,
Proof: proof,
BundleId: bundle.BundleId,
PoolId: bundle.PoolId,
ChainId: bundle.ChainId,
Indices: indices,
}
trustlessItems = append(trustlessItems, trustlessDataItem)
}
return &trustlessItems, nil
}
Database structure & Adapter
How are the data items stored and how do are they indexed?
There are two types:
- DataItemDocument
- IndexDocument.
There will be exactly two tables per pool with pre-defined naming conventions:
DataItemDocument (data_items_pool_{ poolId })
| ID | BundleID | PoolID | FileType | FilePath |
|---|---|---|---|---|
| uint, primary key | int64 | int64 | int | string |
IndexDocument (indices_pool_{ poolId })
| Value | IndexID | DataItemID |
|---|---|---|
| string, primary key | int, primary key | uint |
The IndexID must be saved because there might be multiple indices for a data item, such as block_height and slot_number.
A database adapter interface is used to separate the database implementation from the logic. This approach allows switching databases without modifying anything except the database adapter.
Adapter interface:
type Adapter interface {
Save(bundle *types.Bundle) error
Get(indexId int, key string) (files.SavedFile, error)
GetMissingBundles(lastBundleId int64) []int64
GetIndexer() indexer.Indexer
}
Only three methods are used to interact with the database. When inserting data items, it is crucial to submit them all in a single transaction. This ensures that either all data items of a bundle are saved or none are, preventing incomplete data.
When saving a bundle, the adapter is responsible for the following:
- Convert the bundle's data items into trustless data items using an indexer.
- Upload/Save the trustless data items to a location (this will be done via a FileAdapter).
- Write all necessary information about the data item and its location into the database.
- Finally, insert every index that exists for that specific data item (in case of EthBlobs this would be the
block_heightandslot_number).
File Adapter
The Trustless API can save the trustless data items to various locations, therefore it's required to account for different file types. The FileAdapter is responsible for that.
Currently, there are only two FileAdapter:
- local file
- s3 file
A FileAdapter is only responsible for saving a trustless data item. The corresponding interface looks like the following:
type SaveDataItem interface {
Save(dataitem *types.TrustlessDataItem) (SavedFile, error)
}
How the server works in detail

The crawler has done the difficult part of indexing each bundle, now the server is able to simply retrieve and serve the requested data item from the database.
- A user requests a specific data item with a key. For example, the user executes the following request:
https://{Trustless_API_URL}/beacon/blob_sidecars?block_height=19882011 - Now the server looks up the data item location for that key. Following the given example, the server would call the database adapter with the following arguments:
Get(19882011, EthBlobIndexHeight)EthBlobIndexHeight = 0because theblock_heightis the first index defined inEthBlobs
- With the data items' location, the server either redirects to that location, or serves it directly. This behaviour can be set in the
config.yml. - At this point the server has provided the user with all the necessary information to query for the on-chain Merkle root for that specific data item.
- Finally, the user constructs the local Merkle root hash based on the provided data item from the server and compares it to the on-chain merkle root.
The Trustless Client serves the functionality for 5).